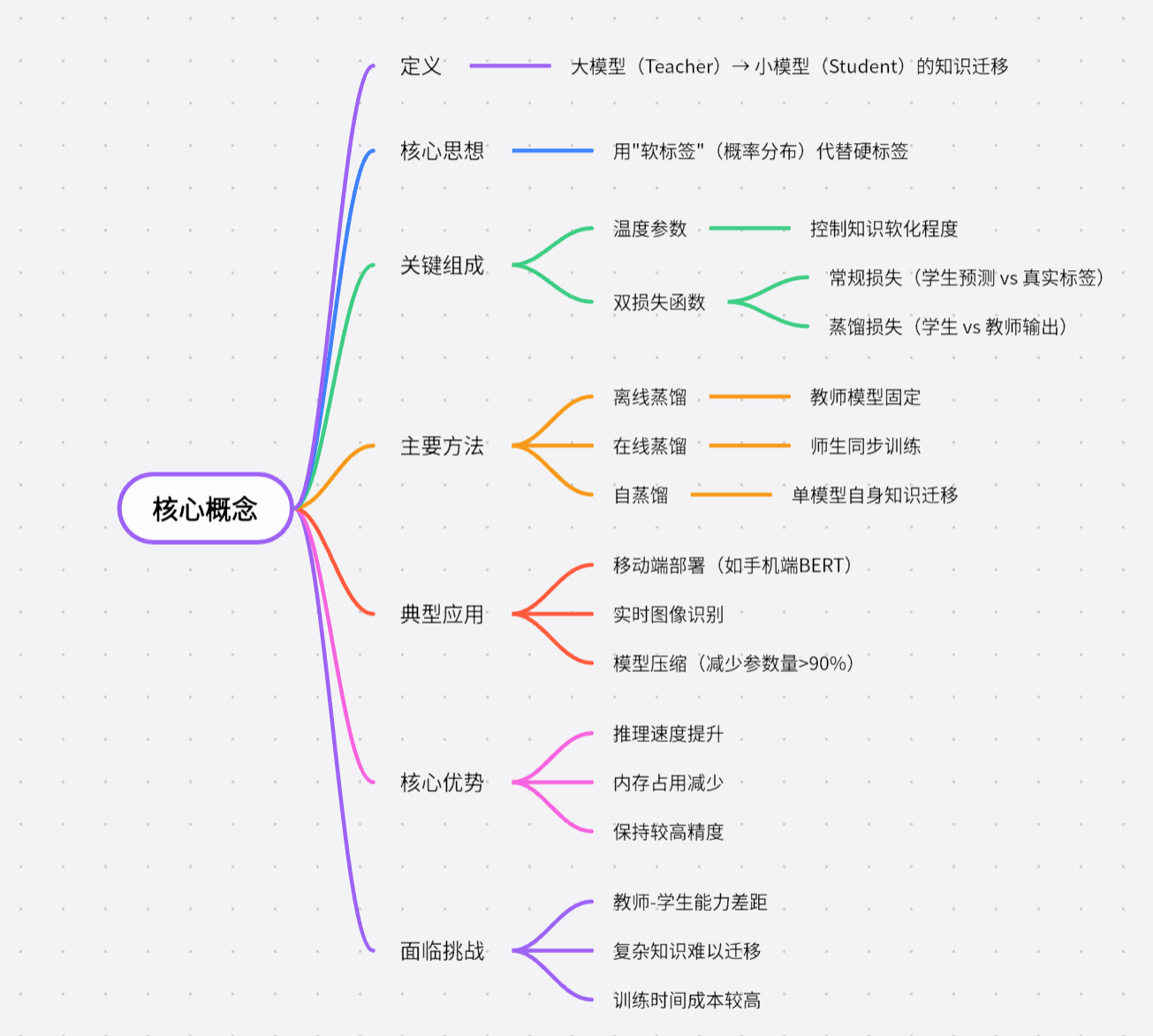
在了解了大模型的基本概念和应用领域后,深入探究其背后的关键技术与架构,能帮助我们更好地理解大模型为何具有如此强大的能力。本文将着重介绍大模型所涉及的核心技术以及常见的架构模式,为进一步学习大模型开发和应用奠定基础。
一、核心技术:大模型的四大支柱
如果把大模型比作一辆超级跑车,那么它的核心技术就是引擎、变速箱、底盘和控制系统。以下四个关键技术缺一不可:
1. Transformer架构:大模型的“乐高积木”
Transformer 是大模型的基石,最初由谷歌在2017年提出。它的核心思想是用注意力机制替代传统的循环神经网络(RNN),解决了长距离依赖问题(比如理解一段话开头和结尾的关系)。
• 关键组件:
• 自注意力机制(Self-Attention):让模型在分析每个词时,能动态关注到其他相关词(比如“苹果”在句子中可能指水果,也可能指公司)。
• 位置编码(Positional Encoding):告诉模型词的顺序信息(比如“猫追狗”和“狗追猫”意义不同)。
• 优势:并行计算能力强,适合处理海量数据,天然适配GPU加速。
2. 注意力机制:大模型的“手电筒”
注意力机制就像一束光,让模型在处理信息时能聚焦在关键部分。
• 举个栗子🌰:当模型看到“小明吃了一个苹果,因为它很饿”,注意力机制会让模型自动关联“吃”和“饿”,而不是去纠结“苹果”的颜色。
• 扩展应用:除了文本,注意力机制还被用于处理图像、语音等多模态数据。
3. 预训练与微调:从“通才”到“专才”
大模型通常分为两个阶段训练:
- 预训练:用海量通用数据(比如维基百科、书籍)训练模型,让它学会语言规律和基础推理能力。
• 经典方法:掩码语言模型(MLM,如BERT)、自回归模型(如GPT)。
- 微调:用特定领域的数据(比如医疗、法律文本)对模型进行针对性优化,让它适应具体任务。
• 效率提升:微调只需少量数据和计算资源,就能让通用模型变成领域专家。
4. 分布式训练:如何“分蛋糕”
训练一个大模型可能需要数千张GPU卡,如何高效协调它们?答案就是分布式训练技术。
• 数据并行:把数据切分成多份,每张卡处理一部分,最后合并结果(类似多人分头抄写同一本书)。
• 模型并行:当模型太大,单张卡放不下时,把模型拆分成多个部分,分配到不同卡上(类似拼图)。
• 混合并行:结合以上两种方式,目前主流大模型(如GPT-4)均采用这种策略。
二、架构设计:大模型的“骨架”如何搭建
如果说技术是燃料,那么架构就是大模型的骨架。一个优秀的架构需要平衡性能、效率和扩展性。
1. 模型规模的扩展:越大越好?
大模型的参数规模从数亿(如BERT)增长到数万亿(如GPT-4),但“大”并非无脑堆砌参数。
• 规模定律(Scaling Laws):研究发现,模型的性能随参数规模、数据量和计算量呈幂律增长。
• 挑战:参数越多,训练成本指数级上升,且可能遇到“性能饱和”问题。
2. 层次结构设计:模块化思维
大模型通常采用分层的模块化设计:
• 基础层:处理原始输入(如分词、嵌入表示)。
• 中间层:多层Transformer堆叠,逐层提取抽象特征。
• 输出层:根据任务生成结果(如文本生成、分类标签)。
• 扩展技巧:通过增加层数(深度)或每层的宽度(神经元数量)来提升模型能力。
3. 工程优化:魔鬼在细节中
大模型的成功离不开工程优化:
• 混合精度训练:用16位浮点数代替32位,节省显存并加速计算。
• 内存管理:通过梯度检查点(Gradient Checkpointing)等技术减少显存占用。
• 推理优化:模型压缩(如量化、剪枝)、动态批处理(Dynamic Batching)提升推理速度。
三、技术挑战与未来方向
尽管大模型表现惊艳,但仍面临诸多挑战:
- 计算资源:训练成本高达数百万美元,中小企业难以负担。
- 数据质量:依赖互联网爬取的数据可能包含偏见和错误。
- 能耗问题:一次训练消耗的电力相当于数百户家庭一年的用电量。
未来可能的突破方向包括:
• 稀疏模型(Sparse Models):让模型只在必要时激活部分参数,降低计算量。
• 多模态融合:将文本、图像、语音统一到一个框架内(如GPT-4V)。
• 绿色AI:通过算法优化减少能耗。
大模型的核心技术与架构设计,就像一台精密的交响乐,需要算法、工程和硬件的完美配合。希望这篇文章能帮你理解大模型的“内在逻辑”。下一期我们将探讨大模型的应用场景与伦理问题,敬请期待!




 AI与大模型
AI与大模型